SQL wird in einer anderen Reihenfolge ausgeführt als es geschrieben wird. Wer das nicht weiß, schreibt Queries die zufällig funktionieren — oder zufällig nicht. Diese SQL Grundlagen räumen mit den häufigsten Denkfehlern auf.
Inhaltsverzeichnis
- 1. Logische Ausführungsreihenfolge vs. Schreibreihenfolge
- 2. Warum Spalten-Aliasse in WHERE nicht funktionieren
- 3. LIMIT ohne ORDER BY ist nicht-deterministisch
- 4. WHERE vs. HAVING: Vor oder nach der Aggregation
- 5. SELECT * — die vier Probleme
- 6. DISTINCT vs. GROUP BY
- 7. ORDER BY mit mehreren Spalten und Ausdrücken
- 8. Professionelle Unterstützung
- 9. Zusammenfassung
- 10. FAQ
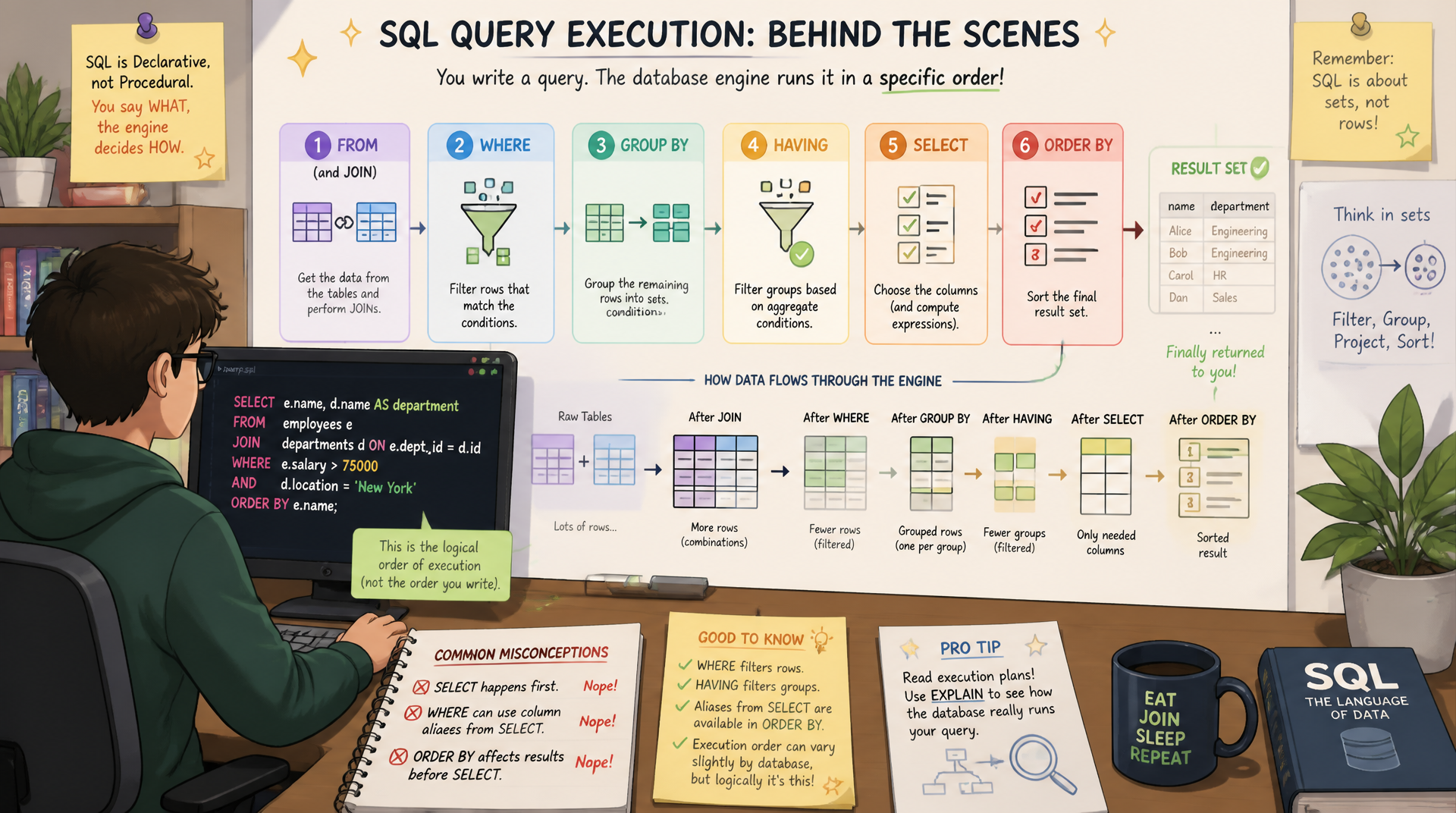
1. Logische Ausführungsreihenfolge vs. Schreibreihenfolge
Der wichtigste Grundsatz beim Verstehen von SQL: Die Reihenfolge, in der man eine Query schreibt, ist nicht die Reihenfolge, in der sie ausgeführt wird. MySQL verarbeitet eine SELECT-Anweisung logisch in dieser Reihenfolge:
-- Logical SQL execution order (NOT the write order):
-- 1. FROM → which table(s) to read
-- 2. JOIN → combine rows from multiple tables
-- 3. WHERE → filter rows before grouping (can use index)
-- 4. GROUP BY → group rows for aggregation
-- 5. HAVING → filter groups after aggregation
-- 6. SELECT → choose which columns to return
-- 7. DISTINCT → remove duplicate rows from SELECT result
-- 8. ORDER BY → sort the result
-- 9. LIMIT → restrict number of rows returned
-- Write order (how you type it):
SELECT status, COUNT(*) AS order_count -- step 6
FROM sales_order -- step 1
WHERE created_at >= '2025-01-01' -- step 3
GROUP BY status -- step 4
HAVING order_count > 10 -- step 5
ORDER BY order_count DESC -- step 8
LIMIT 5; -- step 9Diese Reihenfolge ist der Schlüssel zum Verständnis vieler scheinbar seltsamer SQL-Verhaltensweisen. Sie erklärt, warum manche Dinge funktionieren und andere nicht — zum Beispiel, warum ein Alias aus SELECT nicht in WHERE nutzbar ist, aber in ORDER BY schon.
2. Warum Spalten-Aliasse in WHERE nicht funktionieren
Ein klassischer Denkfehler: Man definiert in SELECT einen Alias und will ihn in WHERE verwenden. Das funktioniert nicht — und der Grund liegt direkt in der logischen Ausführungsreihenfolge. WHERE (Schritt 3) wird vor SELECT (Schritt 6) verarbeitet. Zum Zeitpunkt, an dem WHERE läuft, existiert der Alias noch nicht.
-- This FAILS: alias 'net_total' does not exist when WHERE is evaluated
SELECT grand_total - discount_amount AS net_total
FROM sales_order
WHERE net_total > 100; -- ERROR: Unknown column 'net_total'
-- Correct: repeat the expression in WHERE
SELECT grand_total - discount_amount AS net_total
FROM sales_order
WHERE grand_total - discount_amount > 100;
-- Or use a subquery / CTE to make the alias available:
WITH order_totals AS (
SELECT entity_id,
grand_total - discount_amount AS net_total
FROM sales_order
)
SELECT * FROM order_totals WHERE net_total > 100;In ORDER BY hingegen können Aliasse aus SELECT genutzt werden — das ist ein MySQL-spezifisches Feature, das vom Standard abweicht. Da ORDER BY (Schritt 8) nach SELECT (Schritt 6) kommt, ist der Alias zu diesem Zeitpunkt bekannt. In HAVING (Schritt 5) ist das in MySQL ebenfalls erlaubt, obwohl HAVING vor SELECT kommt — MySQL löst hier den Alias als Extension auf.
-- In MySQL: alias FROM SELECT works in ORDER BY (MySQL extension)
SELECT status, COUNT(*) AS cnt
FROM sales_order
GROUP BY status
HAVING cnt > 5 -- MySQL-specific: alias works in HAVING too
ORDER BY cnt DESC; -- alias works in ORDER BY (logically after SELECT)3. LIMIT ohne ORDER BY ist nicht-deterministisch
Einer der gefährlichsten Denkfehler bei SQL Grundlagen: LIMIT ohne ORDER BY gibt eine beliebige Teilmenge der Ergebnisse zurück — nicht die "ersten" Zeilen in irgendeinem sinnvollen Sinne. MySQL gibt keine Garantie über die Reihenfolge von Zeilen ohne explizites ORDER BY. Die zurückgegebene Teilmenge kann sich von Ausführung zu Ausführung unterscheiden, je nach Ausführungsplan, Buffer-Pool-Zustand oder Paralleloperationen.
-- NON-DETERMINISTIC: results can differ between executions
SELECT entity_id, created_at FROM sales_order LIMIT 10;
-- These 10 rows could be any 10 rows — not necessarily the oldest or newest
-- DETERMINISTIC: always returns the same result
SELECT entity_id, created_at
FROM sales_order
ORDER BY entity_id
LIMIT 10;
-- Always the 10 rows with the lowest entity_id
-- DETERMINISTIC: useful for "latest orders"
SELECT entity_id, created_at, grand_total
FROM sales_order
WHERE status = 'complete'
ORDER BY created_at DESC
LIMIT 10;
-- Always the 10 most recent complete ordersFür Paginierung ist ein fehlendes ORDER BY besonders problematisch: Die Seite 2 könnte Zeilen aus Seite 1 wiederholen oder Zeilen überspringen, weil der Optimizer bei unterschiedlichen Ausführungen unterschiedliche Zugriffspfade wählt. Jede produktive LIMIT-Query braucht ein explizites ORDER BY.
4. WHERE vs. HAVING: Vor oder nach der Aggregation
WHERE und HAVING filtert beide Zeilen — aber zu verschiedenen Zeitpunkten in der logischen Ausführungsreihenfolge. WHERE filtert vor der Aggregation (Schritt 3, vor GROUP BY). Es reduziert die Datenmenge, bevor MySQL überhaupt anfängt zu gruppieren, und kann Indizes nutzen. HAVING filtert nach der Aggregation (Schritt 5, nach GROUP BY). Es kann auf aggregierte Werte (SUM, COUNT, AVG) referenzieren, aber nicht auf Indizes der Ausgangstabelle.
-- WHERE: filters individual rows BEFORE grouping
-- Use for conditions on non-aggregated columns
SELECT status, COUNT(*) AS cnt, SUM(grand_total) AS revenue
FROM sales_order
WHERE created_at >= '2025-01-01' -- index can be used, reduces rows early
GROUP BY status;
-- HAVING: filters groups AFTER aggregation
-- Use for conditions on aggregated values
SELECT customer_id, COUNT(*) AS order_count
FROM sales_order
GROUP BY customer_id
HAVING order_count >= 5; -- filters AFTER counting per customer
-- WRONG: using HAVING where WHERE should be used (no performance issue, but wrong intent)
SELECT status, COUNT(*) AS cnt
FROM sales_order
GROUP BY status
HAVING status = 'complete'; -- works, but should be WHERE status = 'complete'
-- CORRECT combination of both:
SELECT customer_id, COUNT(*) AS order_count, SUM(grand_total) AS total
FROM sales_order
WHERE created_at >= '2024-01-01' -- WHERE: filter by date (before GROUP BY)
GROUP BY customer_id
HAVING total > 500; -- HAVING: filter by aggregated total (after GROUP BY)5. SELECT * — die vier Probleme
SELECT * ist bequem und schnell getippt — aber in Produktionsqueries problematisch. Die vier Hauptprobleme:
1. Bandbreitenverschwendung: MySQL überträgt alle Spalten zum Client, auch wenn die Anwendung nur drei davon benötigt. Bei Tabellen mit 50+ Spalten ist das erheblicher Overhead.
2. Covering-Index-Verlust: Ein Index, der alle benötigten Spalten enthält, erlaubt MySQL das Lesen ausschließlich aus dem Index ohne Table-Lookup. SELECT * verhindert das immer, weil der Index nie alle Spalten enthält.
3. Anwendungsbruch bei Schema-Änderungen: Wenn eine neue Spalte hinzugefügt wird, gibt SELECT * sie plötzlich zurück. Code, der auf Spaltenposition oder eine feste Spaltenanzahl verlässt, bricht ohne ersichtliche Query-Änderung.
4. Lesbarkeit: Eine Query, die explizit SELECT entity_id, status, grand_total schreibt, dokumentiert, was sie tatsächlich braucht. SELECT * lässt das offen.
-- Problematic: SELECT * in production code
SELECT * FROM sales_order WHERE status = 'complete';
-- Returns 60+ columns, prevents covering index usage
-- Better: explicit column list
SELECT entity_id, increment_id, status, grand_total, created_at
FROM sales_order
WHERE status = 'complete';
-- Covering index example: if index exists on (status, grand_total, entity_id)
-- this query reads ONLY from the index, no table lookup needed:
SELECT entity_id, grand_total
FROM sales_order
WHERE status = 'complete'
ORDER BY grand_total DESC;6. DISTINCT vs. GROUP BY
DISTINCT und GROUP BY liefern oft dasselbe Ergebnis, haben aber unterschiedliche Semantik. DISTINCT entfernt Duplikate aus dem gesamten SELECT-Ergebnis. GROUP BY gruppiert Zeilen nach einem oder mehreren Feldern und erlaubt Aggregationen. Für reine Deduplizierung ohne Aggregation sind beide äquivalent — aber GROUP BY drückt die Absicht klarer aus und ist oft der bevorzugte Stil in komplexen Queries.
-- DISTINCT: removes duplicate rows from result
SELECT DISTINCT customer_id FROM sales_order;
-- Returns each customer_id exactly once
-- GROUP BY: same result, but intent is clearer and allows aggregation
SELECT customer_id FROM sales_order GROUP BY customer_id;
-- Same result as DISTINCT, but can be extended:
SELECT customer_id, COUNT(*) AS orders, MAX(grand_total) AS max_order
FROM sales_order
GROUP BY customer_id;
-- DISTINCT on multiple columns (all columns must be identical for deduplication)
SELECT DISTINCT customer_id, status FROM sales_order;
-- Returns unique (customer_id, status) combinations
-- GROUP BY with multiple columns:
SELECT customer_id, status, COUNT(*) AS cnt
FROM sales_order
GROUP BY customer_id, status;
-- Same distinct pairs, plus count per pairEin subtiler Unterschied: SELECT DISTINCT a, b und SELECT a, b GROUP BY a, b liefern dieselben Zeilen, aber die ORDER ist nicht dieselbe. Wer eine bestimmte Sortierung braucht, muss explizit ORDER BY hinzufügen — bei beiden Varianten.
7. ORDER BY mit mehreren Spalten und Ausdrücken
ORDER BY kann mehrere Spalten in Prioritätsreihenfolge sortieren. Die erste Spalte ist die primäre Sortierung, die zweite Spalte bricht Gleichstände auf, und so weiter. Das ist besonders wichtig für Paginierung und Reports, wo nicht-deterministisches Verhalten bei Gleichständen zu inkonsistenten Ergebnissen führt.
-- Multiple ORDER BY columns: primary sort, then secondary for ties
SELECT entity_id, status, grand_total, created_at
FROM sales_order
WHERE status = 'complete'
ORDER BY grand_total DESC, -- primary: highest total first
created_at DESC; -- secondary: most recent first for equal totals
-- ORDER BY with expression (no alias needed)
SELECT entity_id, grand_total, discount_amount
FROM sales_order
ORDER BY grand_total - discount_amount DESC; -- sort by net value
-- ORDER BY with alias (MySQL extension, works because ORDER BY runs after SELECT)
SELECT entity_id,
grand_total - discount_amount AS net_total
FROM sales_order
ORDER BY net_total DESC; -- alias from SELECT usable in ORDER BY
-- ORDER BY column position (avoid: fragile if column order changes)
SELECT entity_id, status, grand_total FROM sales_order ORDER BY 3 DESC;
-- 3 = third column (grand_total). Breaks silently if column order changes.
-- Explicit stable sort for pagination (always include unique column last)
SELECT entity_id, created_at, grand_total
FROM sales_order
ORDER BY created_at DESC, entity_id DESC -- entity_id breaks ties uniquely
LIMIT 20 OFFSET 40; -- page 3 of 20 results per pageDas Beispiel mit entity_id als letztem Sortierschlüssel ist ein wichtiges Muster: Wenn mehrere Zeilen denselben created_at-Wert haben, ist die Reihenfolge ohne zweiten Tiebreaker nicht-deterministisch. Für zuverlässige Paginierung sollte immer eine eindeutige Spalte als letzter Sortschlüssel stehen.
Mironsoft
SQL-Queries die wirklich das tun was sie sollen — Review und Optimierung
Von SQL Grundlagen bis zu komplexen Produktionsqueries: Wir prüfen, ob Sortierung, Filterung, Aggregation und Indexnutzung korrekt und deterministisch implementiert sind.
Query-Review
SELECT *, nicht-deterministisches LIMIT, falsche WHERE/HAVING-Nutzung identifizieren
Performance-Analyse
EXPLAIN lesen, Indexnutzung prüfen und Covering Indexes für häufige Queries konzipieren
Magento SQL
Sales, Catalog und EAV-Tabellen korrekt und effizient abfragen
SQL Grundlagen — Das Wichtigste auf einen Blick
Ausführungsreihenfolge
FROM → JOIN → WHERE → GROUP BY → HAVING → SELECT → DISTINCT → ORDER BY → LIMIT. Nicht die Schreibreihenfolge.
LIMIT ohne ORDER BY
Nicht-deterministisch. Kann bei jeder Ausführung andere Zeilen zurückgeben. Immer ORDER BY angeben.
WHERE vs. HAVING
WHERE filtert vor Aggregation (kann Index nutzen). HAVING filtert nach Aggregation (auf aggregierte Werte).
SELECT *
Bandbreitenverschwendung, Covering-Index-Verlust und Bruchrisiko bei Schema-Änderungen.
9. Zusammenfassung
SQL Grundlagen bedeuten nicht, SELECT-Syntax auswendig zu kennen. Es bedeutet, die logische Ausführungsreihenfolge zu verstehen — und daraus abzuleiten, warum Aliasse in WHERE nicht funktionieren, warum LIMIT ohne ORDER BY gefährlich ist, warum WHERE und HAVING nicht austauschbar sind und warum SELECT * in Produktionscode vermieden werden sollte.
Die meisten SQL-Fehler sind keine Syntaxfehler — sie sind Denkfehler. Eine Query, die korrekte Ergebnisse liefert, aber auf nicht-deterministischem Verhalten basiert, ist ein wartender Bug. Eine Query mit HAVING statt WHERE auf einer nicht-aggregierten Spalte funktioniert, aber verhindert Indexnutzung ohne Fehlermeldung. Diese subtilen Probleme entstehen fast immer aus einem unklaren Verständnis der Ausführungsreihenfolge.