ReadableStream, WritableStream & TransformStream
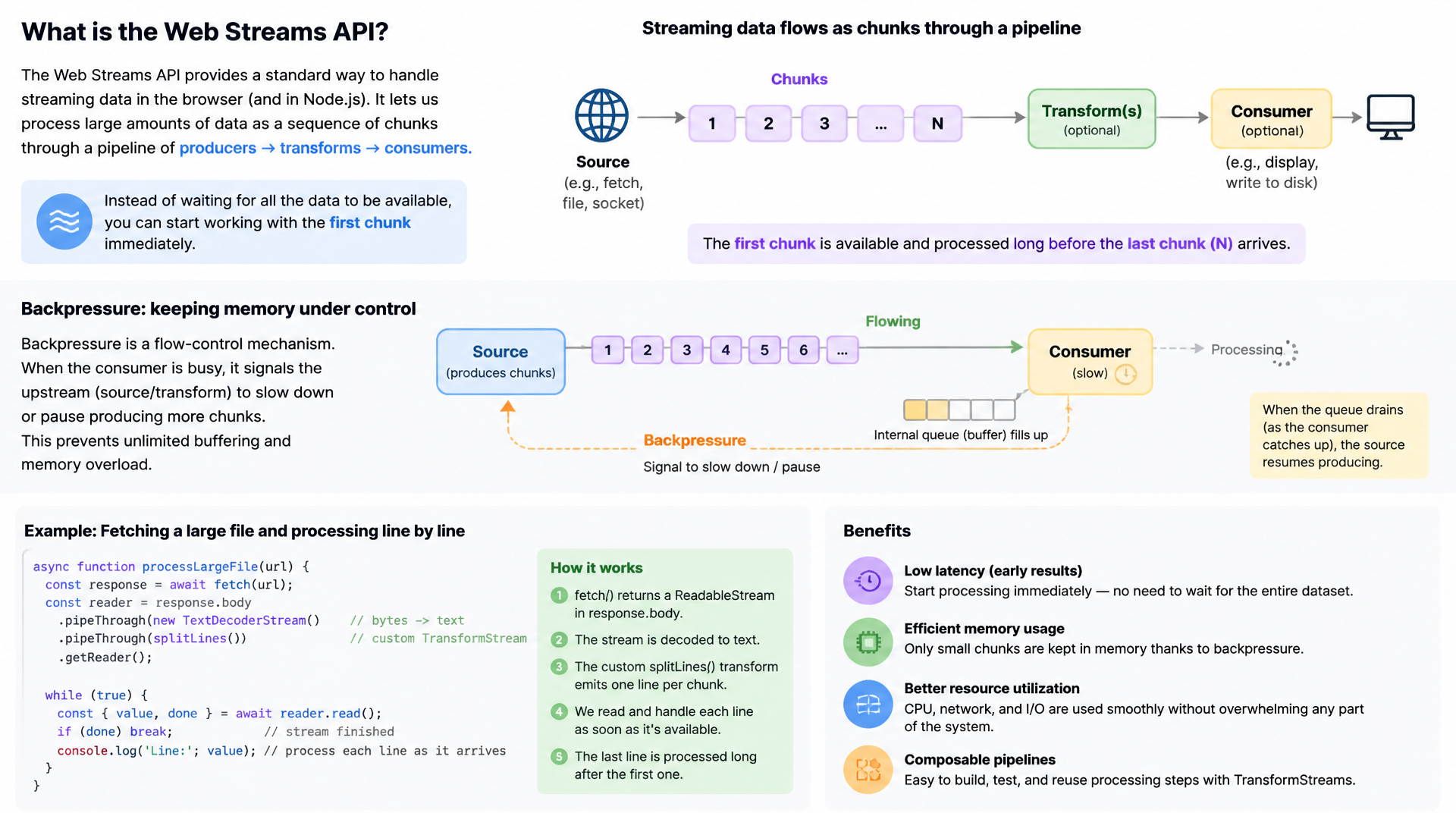
Wer große Datenmengen in JavaScript verarbeitet, hat lange alles in den Speicher geladen, bevor er damit arbeiten konnte. Die Web Streams API ändert das: Daten fließen als Chunks durch eine Pipeline, Backpressure verhindert Speicher-Überlastung, und der erste Chunk ist verfügbar, bevor der letzte angekommen ist.
Inhaltsverzeichnis
- 1. Warum Streams und nicht einfach await response.json()?
- 2. ReadableStream: Datenquellen als Stream
- 3. Fetch API und Streams: Antworten stückweise lesen
- 4. TransformStream: Daten in der Pipeline transformieren
- 5. WritableStream: Chunks in Ziele schreiben
- 6. Backpressure: Fluss kontrollieren, Speicher schonen
- 7. Pipelines mit pipeThrough und pipeTo
- 8. Streams in Node.js: Web Streams vs. Node Streams
- 9. Streams-Typen im direkten Vergleich
- 10. Zusammenfassung
- 11. FAQ
1. Warum Streams und nicht einfach await response.json()?
Für die meisten API-Aufrufe ist await response.json() die richtige Wahl: kompakt, lesbar und ausreichend. Aber sobald die Datenmenge wächst – große CSV-Exporte, Video-Streams, Server-Sent Events, LLM-Antworten, Datei-Uploads – entsteht ein fundamentales Problem: Die gesamte Antwort muss im Speicher gehalten werden, bevor ein einziges Byte verarbeitet werden kann. Bei einem 500-MB-CSV aus einer Reporting-API bedeutet das 500 MB im Browser-Heap. Die JavaScript Streams API löst dieses Problem grundlegend anders: Daten fließen als kleine Chunks durch eine Pipeline, und der Entwickler verarbeitet jeden Chunk sofort, während der nächste noch geladen wird.
Der zweite, oft übersehene Vorteil ist die Time-to-First-Byte-Verbesserung aus Nutzersicht. Wenn ein Server eine lange Antwort sendet, kann die Anwendung mit einem ReadableStream den ersten Datenchunk sofort anzeigen – auch wenn die restlichen 90% noch übertragen werden. Das ist der Unterschied zwischen einer Anwendung, die nach 3 Sekunden schlagartig etwas anzeigt, und einer Anwendung, die nach 300 Millisekunden die ersten Zeilen anzeigt und den Rest inkrementell nachlädt. LLM-APIs nutzen dieses Prinzip: Die Antwort erscheint Token für Token, weil der Server einen ReadableStream sendet, der die Anwendung sofort rendern kann.
2. ReadableStream: Datenquellen als Stream
Ein ReadableStream ist eine Datenquelle, die Chunks sequenziell produziert. Man erzeugt ihn mit dem Konstruktor und einer start(controller)-Funktion: Innerhalb dieser Funktion ruft man controller.enqueue(chunk) auf, um Daten in die Queue zu stellen, und controller.close(), wenn die Quelle erschöpft ist. Für asynchrone Quellen – Datenbankabfragen, Datei-Reads, externe APIs – nutzt man die optionale pull(controller)-Methode, die aufgerufen wird, wenn der Konsument bereit ist, den nächsten Chunk zu empfangen. Das ist die Grundlage für Backpressure.
Ein ReadableStream kann nur einmal gelesen werden – er ist kein Observable, das man beliebig oft subscriben kann. Um denselben Stream an zwei Konsumenten zu senden, nutzt man stream.tee(), das zwei identische ReadableStreams erzeugt. Das ist nützlich, wenn man dieselbe Antwort gleichzeitig in die IndexedDB schreiben und auf dem Bildschirm anzeigen möchte, ohne die Anfrage zweimal zu senden. Lesen eines ReadableStreams geschieht entweder über den Reader-API (const reader = stream.getReader()) oder per for await...of-Schleife, die den Stream als asynchronen Iterator behandelt.
// ReadableStream — custom source with async generation
function createCounterStream(max) {
let count = 0;
return new ReadableStream({
// start() called once — can enqueue immediately or return a Promise
start(controller) {
console.log('[Stream] Source initialized');
},
// pull() called when consumer is ready for more data (backpressure)
async pull(controller) {
if (count >= max) {
controller.close();
return;
}
// Simulate async data source (database, file, API)
await new Promise((r) => setTimeout(r, 50));
controller.enqueue({ index: count, value: count * count });
count++;
},
cancel(reason) {
console.log('[Stream] Consumer cancelled:', reason);
},
});
}
// Consume with for-await-of — clean, linear async code
async function processStream() {
const stream = createCounterStream(10);
for await (const chunk of stream) {
console.log(`Chunk ${chunk.index}: ${chunk.value}`);
// Process each chunk as it arrives — no need to wait for all 10
}
console.log('[Stream] Done');
}
3. Fetch API und Streams: Antworten stückweise lesen
Die response.body-Eigenschaft eines Fetch-Ergebnisses ist ein ReadableStream. Das bedeutet, dass jede HTTP-Antwort bereits als Stream verfügbar ist, ohne dass ein eigener Stream erzeugt werden muss. Für den häufigsten Anwendungsfall – Text-Streaming von einem LLM-API wie der OpenAI-API oder Claude-API – liest man den Stream mit einem TextDecoder-Reader aus und verarbeitet jeden Text-Chunk sofort. Der Nutzer sieht Text erscheinen, während der Server noch antwortet.
Das Streaming von großen binären Dateien – Downloads, Video-Segmente, Zip-Archive – folgt demselben Muster mit einem Unterschied: Hier ist das Ziel nicht der DOM, sondern ein WritableStream oder eine Cache-API-Entry. Statt den gesamten ArrayBuffer im Speicher zu halten, schreibt man jeden Chunk sofort in den Ziel-Speicher. Die Kombination aus response.body.pipeThrough() und einem TransformStream für die Verarbeitung und pipeTo() für das Ziel ist das zentrale Muster für effiziente Datenverarbeitung mit der JavaScript Streams API.
4. TransformStream: Daten in der Pipeline transformieren
Ein TransformStream ist ein Mittler in einer Stream-Pipeline: Er hat einen Readable- und einen Writable-End. Was auf dem Writable-Ende hineinkommt, wird transformiert und auf dem Readable-Ende herausgegeben. Der Konstruktor nimmt Transformer-Methoden: transform(chunk, controller) wird für jeden eingehenden Chunk aufgerufen, kann ihn transformieren und mit controller.enqueue() weiterreichen. flush(controller) wird aufgerufen, wenn der Upstream geschlossen wurde, und erlaubt das Hinausschreiben verbleibender Daten aus einem internen Puffer.
TransformStreams sind composable: Mehrere TransformStreams lassen sich zu einer Pipeline verketten, jeder mit einer klaren, begrenzten Aufgabe. Ein häufiges Muster für die Verarbeitung von Server-Sent Events: Ein erster TransformStream dekodiert Bytes zu Text (new TextDecoderStream()), ein zweiter splittet den Text am Newline-Zeichen in Zeilen, ein dritter filtert Zeilen, die mit data: beginnen, ein vierter parsed den JSON-Inhalt. Jede dieser Transformationen ist eine klare Funktion, die man separat testen kann. Die Streams API macht diese Pipeline-Architektur zur Laufzeit effizient durch Backpressure-Propagierung über alle Stufen.
// Streaming fetch with TransformStream pipeline
// Pattern: LLM token streaming (works with OpenAI, Claude, Ollama)
async function streamLLMResponse(prompt) {
const response = await fetch('/api/chat', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ prompt }),
});
if (!response.body) throw new Error('No body');
// Pipeline: bytes → text → SSE lines → JSON data chunks
const lineStream = new TransformStream({
buffer: '',
transform(chunk, controller) {
this.buffer += chunk;
const lines = this.buffer.split('\n');
this.buffer = lines.pop(); // keep incomplete last line
for (const line of lines) {
if (line.startsWith('data: ') && line !== 'data: [DONE]') {
try {
const data = JSON.parse(line.slice(6));
controller.enqueue(data.choices?.[0]?.delta?.content ?? '');
} catch {
// Skip malformed JSON lines
}
}
}
},
flush(controller) {
// Process any remaining buffered content
if (this.buffer.startsWith('data: ')) {
controller.enqueue(this.buffer.slice(6));
}
},
});
const readable = response.body
.pipeThrough(new TextDecoderStream())
.pipeThrough(lineStream);
// Render tokens to DOM as they arrive
const output = document.getElementById('output');
for await (const token of readable) {
output.textContent += token;
}
}
5. WritableStream: Chunks in Ziele schreiben
Ein WritableStream ist das Ziel einer Stream-Pipeline. Er definiert, was mit jedem Chunk passiert, wenn er ankommt: In eine Datei schreiben, an einen WebSocket senden, in IndexedDB speichern, an einen Service Worker weiterreichen. Der Konstruktor nimmt einen Sink-Objekt mit den Methoden start(controller), write(chunk, controller), close(controller) und abort(reason). Die write()-Methode kann ein Promise zurückgeben – wenn sie das tut, wartet der Upstream auf das Abschluss-Signal, bevor er den nächsten Chunk sendet. Das ist die Backpressure-Mechanik auf der Sink-Seite.
Ein praktisches Beispiel ist das Streaming-Upload-Pattern: Statt eine große Datei vollständig in den Speicher zu lesen und dann als einzelne Anfrage zu senden, liest man sie mit der File System Access API als ReadableStream und sendet sie mit einem WritableStream, der intern einen Fetch-Request aufbaut. Das erlaubt Uploads von Dateien, die größer sind als der verfügbare JavaScript-Heap. Die WritableStream-Abstraktion trennt dabei sauber zwischen dem "Wie produziere ich Daten?" (ReadableStream) und dem "Wohin sende ich die Daten?" (WritableStream).
6. Backpressure: Fluss kontrollieren, Speicher schonen
Backpressure ist das wichtigste Konzept der JavaScript Streams API, das sie von einfacheren Event-Emitter-Modellen unterscheidet. Das Problem ohne Backpressure: Wenn ein Producer Daten schneller erzeugt als der Consumer sie verarbeiten kann, sammeln sich Chunks im Speicher an – im schlimmsten Fall bis zum Out-of-Memory-Fehler. Die Streams API löst das durch ein Queuing-Strategie-System mit einem High-Watermark-Wert.
Jeder Stream hat eine interne Queue mit einem Füllstand. Wenn die Queue den High-Watermark-Wert überschreitet, gibt der Stream ein desiredSize-Feedback zurück, das dem Producer signalisiert, die Produktion zu verlangsamen oder zu stoppen. Bei ReadableStreams stoppt der Browser, die pull()-Methode aufzurufen, bis der Consumer Chunks aus der Queue gelesen hat. Bei WritableStreams gibt die write()-Methode ein Promise zurück, das erst resolved, wenn der Downstream bereit ist. Diese automatische Backpressure-Propagierung durch eine gesamte Pipeline aus ReadableStream → TransformStream → WritableStream ist das, was die Streams API für großvolumige Datenverarbeitung geeignet macht.
// WritableStream with backpressure and pipeline composition
// Pattern: streaming CSV upload with progress tracking
function createProgressWritableStream(onProgress) {
let bytesWritten = 0;
return new WritableStream({
write(chunk) {
// write() returning a Promise applies backpressure:
// upstream waits until this resolves before sending next chunk
return new Promise((resolve) => {
bytesWritten += chunk.length;
onProgress(bytesWritten);
// Simulate async I/O (IndexedDB write, WebSocket send, etc.)
setTimeout(resolve, 10);
});
},
close() {
console.log(`[WritableStream] Completed: ${bytesWritten} bytes total`);
},
abort(reason) {
console.error('[WritableStream] Aborted:', reason);
},
});
}
async function uploadFileWithProgress(file, onProgress) {
const [progressStream] = [createProgressWritableStream(onProgress)];
// File.stream() returns a ReadableStream — no need to load file into memory
await file.stream()
.pipeThrough(new TransformStream({
// Example: count lines in CSV while uploading
transform(chunk, controller) {
controller.enqueue(chunk); // pass through unchanged
},
}))
.pipeTo(progressStream);
}
7. Pipelines mit pipeThrough und pipeTo
pipeThrough(transformStream) und pipeTo(writableStream) sind die Methoden, die Stream-Pipelines komponierbar machen. pipeThrough() nimmt einen TransformStream, verbindet den Writable-End mit dem aktuellen ReadableStream und gibt den Readable-End des TransformStream zurück. Das Ergebnis ist ein neuer ReadableStream, auf dem man weitere pipeThrough()-Aufrufe verketten kann. pipeTo() beendet die Pipeline und gibt ein Promise zurück, das resolved, wenn der gesamte Datenstrom das Ziel erreicht hat oder ein Fehler aufgetreten ist.
Fehlerbehandlung in Stream-Pipelines ist explizit: Wenn ein TransformStream eine Exception wirft oder controller.error() aufruft, propagiert der Fehler durch die gesamte Pipeline. Sowohl der Upstream-ReadableStream als auch der Downstream-WritableStream werden fehlerhaft beendet. Das pipeTo()-Promise wird mit dem Fehler rejected. Im Gegensatz zu tief verschachtelten Promise-Ketten ist die Fehlerquelle in einer Stream-Pipeline durch die Stage des TransformStream klar identifizierbar. Das AbortController-Pattern ist ebenfalls vollständig unterstützt: Ein AbortSignal kann an pipeTo() übergeben werden und bricht die gesamte Pipeline ab.
8. Streams in Node.js: Web Streams vs. Node Streams
Node.js hat seit seiner Entstehung ein eigenes Stream-System. Die Web Streams API (ReadableStream, WritableStream, TransformStream) ist eine separate, browserkompatible API, die seit Node.js 18 als stable verfügbar ist. Die beiden Systeme existieren parallel, sind aber über Adapter interoperabel: Readable.toWeb(nodeReadable) konvertiert einen Node.js Readable Stream zu einem Web ReadableStream. Readable.fromWeb(webReadable) macht die Umkehrung. Das ist wichtig für Bibliotheken, die sowohl im Browser als auch in Node.js laufen sollen.
Für neue Node.js-Projekte, die auch im Browser-Kontext (Edge Functions, Cloudflare Workers, Deno) laufen sollen, empfiehlt sich die konsequente Nutzung der Web Streams API statt der Node.js-spezifischen Streams. Cloudflare Workers und Deno unterstützen ausschließlich Web APIs – Node.js-spezifische Streams sind dort nicht verfügbar. Die JavaScript Streams API ist damit nicht nur eine Browser-API, sondern der universelle Standard für Streaming in modernen JavaScript-Laufzeitumgebungen.
9. Streams-Typen im direkten Vergleich
Die drei Stream-Typen der JavaScript Streams API haben klar abgegrenzte Rollen. Ihre Eigenschaften und Anwendungsfälle im Überblick:
| Stream-Typ | Rolle | Wichtige Methoden | Typischer Einsatz |
|---|---|---|---|
| ReadableStream | Quelle — produziert Chunks | getReader(), pipeThrough(), pipeTo(), tee() | Fetch-Body, Datei lesen, Custom Generator |
| WritableStream | Ziel — konsumiert Chunks | getWriter(), write(), close(), abort() | IndexedDB-Write, WebSocket, DOM-Append |
| TransformStream | Middleware — transformiert Chunks | readable, writable (beide Ends) | Decode, Compress, Parse, Filter, Encrypt |
| TextDecoderStream | Spezialisierter TransformStream | Encoding-Option im Konstruktor | Bytes → String für Text-Protokolle |
| TextEncoderStream | Spezialisierter TransformStream | UTF-8 encoding built-in | String → Bytes für Binary-Protokolle |
Die eingebauten Streams TextDecoderStream und TextEncoderStream sind spezialisierte TransformStreams, die die häufigsten Encoding-Aufgaben abdecken, ohne dass ein benutzerdefinierter Transformer implementiert werden muss. Für Kompression und Dekompression gibt es CompressionStream und DecompressionStream mit Unterstützung für gzip, deflate und deflate-raw. Diese eingebauten Streams API-Komponenten können direkt in Pipeline-Chains genutzt werden und sparen erheblich Boilerplate-Code gegenüber manuellen Implementierungen.
Mironsoft
JavaScript-Datenverarbeitung, Streaming-APIs und performante Web-Anwendungen
Große Datenmengen effizient verarbeiten?
Wir implementieren Streams-basierte Datenverarbeitungs-Pipelines für LLM-Streaming, große Datei-Uploads, Echtzeit-Feeds und CSV-Exporte — speicher-effizient und mit minimaler Time-to-First-Byte.
LLM-Streaming
Token-by-Token-Rendering mit Fetch Streams und Server-Sent Events für AI-Chat-Interfaces
Datei-Pipelines
Große CSV- und Excel-Exporte ohne Speicher-Engpässe — ReadableStream direkt zum Download
Edge Functions
Streaming-Responses für Cloudflare Workers und Vercel Edge — Web Streams API konform
10. Zusammenfassung
Die JavaScript Streams API – ReadableStream, WritableStream und TransformStream – ist das standardisierte Modell für chunk-basierte Datenverarbeitung im Browser und in modernen JavaScript-Laufzeiten. Statt Daten vollständig in den Speicher zu laden, fließen sie als Chunks durch eine Pipeline, die durch Backpressure automatisch reguliert wird. Die Fetch-API integriert Streams nahtlos: response.body ist ein ReadableStream, der sofort verarbeitet werden kann. TransformStreams verketten sich zu Pipelines für Dekodierung, Parsing, Filterung und Transformation in einer lesbaren, modularen Architektur.
Die Anwendungsfälle reichen von LLM-Token-Streaming und Server-Sent-Events-Parsing über große CSV-Exporte bis hin zu Streaming-Uploads und Echtzeit-Datenverarbeitung. Die Kompatibilität mit Node.js 18+, Cloudflare Workers, Deno und allen modernen Browsern macht die Web Streams API zum universellen Standard für Streaming in JavaScript – unabhängig davon, wo der Code läuft. Wer Streams heute in seine Architektur einplant, schreibt Code, der ohne Anpassung in allen aktuellen und zukünftigen JavaScript-Laufzeitumgebungen läuft.
JavaScript Streams API — Das Wichtigste auf einen Blick
Drei Typen
ReadableStream (Quelle), WritableStream (Ziel), TransformStream (Middleware). Kombiniert mit pipeThrough() und pipeTo() zur Pipeline.
Backpressure
Automatische Flussregulierung durch High-Watermark und desiredSize. Verhindert Speicher-Überlastung bei schnellen Producern und langsamen Consumern.
Fetch Integration
response.body ist ein ReadableStream. TextDecoderStream, CompressionStream und TransformStream direkt in der Pipeline — kein manuelles Puffern nötig.
Universell
Node.js 18+, Deno, Cloudflare Workers und alle modernen Browser. Web Streams API ist der plattformübergreifende Standard — kein Lock-in.